
「set型ってリスト型やタプル型とどのように違うの?」
「set型ってどんな機能があるの?」
といったお悩みを抱えている方は多いのではないでしょうか?
pythonを勉強し始めた当初はset型やリスト型、タプル型、辞書型などの区別がつきませんでした。
どれも同じような機能だろうと思っていましたが、set型にはset型にしかない機能が備わっています。
この記事ではset型とは何なのか?どのように使うのか?等を初心者の方でもわかるように解説していきます。
set型とは?
そもそもset型とは何なのか?
別名集合型とも言い、リスト型や辞書型などと同様複数の要素を一つにまとめて操作することが可能なデータ型です。
set型はリスト型などと異なる点として下記2点があります。
- 重複する要素を持たない
- 要素に順番がない
上記set型の特徴が本当なのか実際のコードを使用して見てみましょう。
特徴1:重複する要素を持たない
set型の特徴の一つ目である重複する要素を持たない点をまず見ていきます。
その前にset型の基本的な使用方法について解説しておきます。
【使用方法】
set1=set(['佐藤','鈴木','高橋','田中','伊藤'])
print(set1)【実行結果】
{'伊藤', '高橋', '佐藤', '鈴木', '田中'}使用方法は上記のようにset()を使用することでset型の変数を作成することが可能となります。
ここではリストをsetに変更しています。
では仮にこのリスト内に重複要素を含んでいた場合はどうなるのでしょうか?
【コード】
set1=set(['佐藤','鈴木','伊藤','高橋','田中','伊藤'])
print(set1)【実行結果】
{'高橋', '田中', '佐藤', '伊藤', '鈴木'}上記のように「伊藤」という文字列が2つ存在していましたが、出力すると1つとなっていて重複要素が削除されたことが分かると思います。
特徴2:要素に順番がない
次にset型の変数の要素には順番がないことを確認していきます。
【コード】
set1=set("一文字ずつ分解されます")
print(set1)【実行結果】
{'一', 'つ', '文', '分', 'れ', 'さ', 'す', 'ま', '解', '字', 'ず'}上記コードは文字列からset型の変数を作成しています。
文字列は「一文字ずつ分解されます」となっていますが、set型の変数になった途端、順番がめちゃくちゃになった要素が入っていることが分かります。
因みにリスト型の場合下記のように順番に並んで出力されていることが分かると思います。
【コード】
list1=list("一文字ずつ分解されます")
print(list1)【実行結果】
['一', '文', '字', 'ず', 'つ', '分', '解', 'さ', 'れ', 'ま', 'す']set型の機能一覧
次にset型の機能について紹介していきます。
- 要素の追加
- 要素の削除(一部削除)
- 要素の削除(全削除)
- 要素数の取得
要素の追加
set型の変数に要素を追加する方法としてadd()を使用する方法があります。
【使用方法】
set1=set(['佐藤','鈴木','高橋','田中','伊藤'])
set1.add('渡辺')
print(set1)【実行結果】
{'田中', '高橋', '伊藤', '渡辺', '佐藤', '鈴木'}上記のように新しく「渡辺」という文字列が追加されたことが分かると思います。
そしてここで覚えておきたいのは、要素の追加の際に既に同様の要素があったら追加することができないという点です。
set型は重複要素を含まないという特徴があったと思いますが、その影響で重複している要素の追加ができないのです。
実際のコードとして下記のように重複要素の追加ができていないことが分かると思います。
【コード】
set1=set(['佐藤','鈴木','高橋','田中','伊藤'])
set1.add('田中')
print(set1)【実行結果】
{'鈴木', '伊藤', '高橋', '田中', '佐藤'}要素の削除(一部削除)
次に要素の削除についてです。
まず初めに解説するのは指定した要素のみ削除するという方法です。
【使用方法】
set1=set(['佐藤','鈴木','高橋','田中','伊藤'])
set1.remove('佐藤')
print(set1)【実行結果】
{'伊藤', '鈴木', '田中', '高橋'}上記のようにremove()を使用することで、削除したい要素を指定することで削除が可能となります。
要素の削除(全削除)
次に解説するのは要素の全削除の方法です。
先ほどは指定した要素のみを削除していましたが、ここではすべての要素を削除する方法について解説していきます。
【使用方法】
set1=set(['佐藤','鈴木','高橋','田中','伊藤'])
set1.clear()
print(set1)【実行結果】
set()上記が全削除する方法で、clear()を使用しています。
削除後の実行結果として「set()」と表示されていますが、何も入っていないset型変数はこのように出力されるため、全削除がうまくいったことが分かります。
因みに少し脱線しますが、何も入っていない空のset型変数を作成したいとなった場合は下記のようにすると作成することができます。
set1=set()要素数の取得
最後に要素数の取得方法について解説していきます。
要素数を数えたい場合はlen()を使用します。
【使用方法】
set1=set(['佐藤','鈴木','高橋','田中','伊藤'])
print(len(set1))【実行結果】
5上記のようにset型の変数内の要素数5が出力されていることが分かると思います。
集合演算
set型は別名集合型とも言いますが、その名の通り下記集合を検索するのにも使用可能です。
- 和集合
- 差集合
- 積集合
- 対象差集合(排他的論理和集合)
和集合
和集合は下記の図から分かる通りA集合、B集合両方の要素を取得するものです。
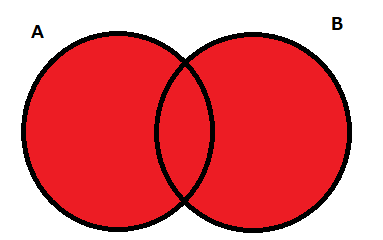
これを計算で求めるとなった場合「|」を使用するかunion()を使用する方法があります。
それぞれ見ていきましょう。
まず「|」を使用した場合は下記のように記載します。
【使用方法】
A=set(['佐藤','鈴木','高橋','田中','伊藤'])
B=set(['渡辺','鈴木','高橋','山本','伊藤'])
AB=A | B
print(AB)【実行結果】
{'佐藤', '田中', '渡辺', '伊藤', '山本', '高橋', '鈴木'}次にunion()を使用する方法は下記となります。
【使用方法】
A=set(['佐藤','鈴木','高橋','田中','伊藤'])
B=set(['渡辺','鈴木','高橋','山本','伊藤'])
AB=A.union(B)
print(AB)こちらの実行結果も先ほどの「|」と同様のものとなります。
どちらもコード量的には同じぐらいですので、自分の使いやすい方を使用されると良いと思います。
差集合
次に差集合ですが、こちらはA集合からB集合の要素を抜いた場合の集合となります。
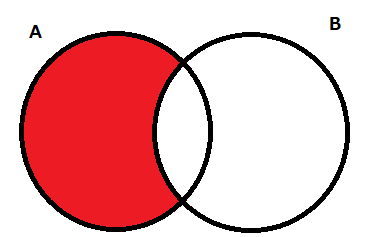
差集合は「–」かdifference()を使用することで求めることができます。
まず「–」を使用した場合ですと下記のようになります。
【使用方法】
A=set(['佐藤','鈴木','高橋','田中','伊藤'])
B=set(['渡辺','鈴木','高橋','山本','伊藤'])
AB=A - B
print(AB)【実行結果】
{'田中', '佐藤'}Aに重複している要素を含めてBの集合が削除された結果が出力されていることが分かるかと思います。
そしてdifference()で差集合を求める方法は下記の通りとなります。
【使用方法】
A=set(['佐藤','鈴木','高橋','田中','伊藤'])
B=set(['渡辺','鈴木','高橋','山本','伊藤'])
AB=A.difference(B)
print(AB)積集合
次に解説するのが積集合です。
こちらは集合Aと集合Bの重複部分のみを出力する集合となります。
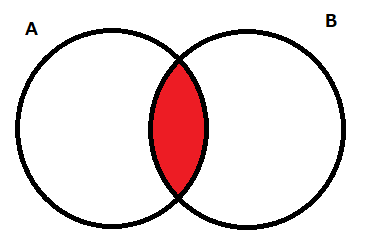
積集合は「&」かintersection()を使用することで求めることができます。
「&」を使用して積集合を求める場合は下記のように記載します。
【使用方法】
A=set(['佐藤','鈴木','高橋','田中','伊藤'])
B=set(['渡辺','鈴木','高橋','山本','伊藤'])
AB=A & B
print(AB)【実行結果】
{'鈴木', '高橋', '伊藤'}重複している要素を1つづつ出力しています。
intersection()を使用した場合は下記となります。
【使用方法】
A=set(['佐藤','鈴木','高橋','田中','伊藤'])
B=set(['渡辺','鈴木','高橋','山本','伊藤'])
AB=A.intersection(B)
print(AB)対象差集合(排他的論理和集合)
最後に解説するのは対象差集合またの名を排他的論理和集合です。
高校とかで勉強した方もいるかもしれませんが、集合A、集合Bの重複していない部分の要素を出力する集合となります。
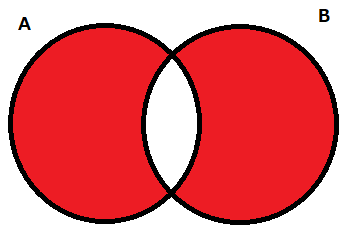
対象差集合(排他的論理和集合)は「^」もしくはsymmetric_difference()を使用することで求めることができます。
まず「^」を使用しての求め方を記載します。
【使用方法】
A=set(['佐藤','鈴木','高橋','田中','伊藤'])
B=set(['渡辺','鈴木','高橋','山本','伊藤'])
AB=A ^ B
print(AB)【実行結果】
{'山本', '田中', '佐藤', '渡辺'}重複要素のみ排除されていることが分かるかと思います。
symmetric_difference()を使用した場合は下記となります。
【使用方法】
A=set(['佐藤','鈴木','高橋','田中','伊藤'])
B=set(['渡辺','鈴木','高橋','山本','伊藤'])
AB=A.symmetric_difference(B)
print(AB)まとめ
この記事ではpythonのset型について解説してきました。
- set型とは?
- set型の機能一覧
- 集合演算
set型はリスト型や辞書型に似た部分もたくさんありますが、set型にしかない特徴として重複要素を持たない・順番がないといったものがありました。
リスト型や辞書型と区別のつかないという方はこの機会にぜひ覚えていってください。
以上で今回の解説を終了させていただきます。


コメント