
スクレイピングという機能についてご存じでしょうか?
スクレイピングとはサイト操作を自動で行うことができる機能の事です。
例えば、「定期的にとあるサイトからファイルをダウンロードしたい。」といったことはありませんか?
私も初めてこのスクレイピングという機能を使用するとなった際は、定期的にバージョンアップされるソフトのファイルをサイトから自動でダウンロードできるようなツールを作成しました。
それまでpythonは大学の卒業研究で少し触った程度ですので、分からないことも多く結構作成に時間がかかったことを覚えています。
そこでこの記事ではそういった方に向けてスクレイピングの操作に必要な準備や大まかなコードの書き方について解説していきます。
スクレイピングの準備
ではまずスクレイピングを実施するのに必要な準備を始めたいと思います。
因みに今回私が実施した環境はpythonのバージョンが3.11.2、edgeは115.0.1901.203というバージョンです。
また今回実施するスクレイピングはedgeを使用するため、そのためのdriverを入れる必要があります。
なのでedgeのバージョンをまず確認しておきてください。
バージョンはedge起動して下記の「・・・」→「設定」の順に押下します。
そして起動した画面の左端に下記のような「Microsoft Edgeについて」という項目があるため、それをクリックします。
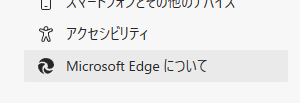
すると下記のようなバージョンが表示されるため、このバージョンに沿ったdriverをダウンロードします。

driveは下記のサイトにまずアクセスして、先ほど調べたバージョンに対応したものを選択する。

クリックしたらダウンロードが開始されるため、完了したらzipファイルを解凍します。
解凍したら「msedgedriver.exe」とかいうファイルができるため、これを任意の場所に保管します。
以降edgeでスクレイピングを実施する際に使用するため、大切に保管しておいてください。
次にseleniumというwebブラウザーを自動化するためのツールを入れていきます。
これはコマンドプロンプトを起動して単純に「pip install selenium」でインスト―ルすることが可能です。
edgeを起動してみる
では準備も完了したので、まずedgeを自動で起動させてみましょう。
適当にテキストファイルを作成して、拡張子をpyとすることでpythonファイルは作成できます。
そしてその中に下記のコードを入力してみてください。
from selenium import webdriver
driver = webdriver.Edge(r"D:\program\python\edgedriver_win64\msedgedriver.exe")
driver.get('https://www.data.jma.go.jp/obd/stats/data/mdrr/docs/csv_dl_format_prenh.html')
因みに今回アクセスするサイトは気象庁のサイトで、先ほどダウンロードした「msedgedriver.exe」ファイルの保存場所は「D:\program\python\edgedriver_win64\」内となっています。
これで後はpythonファイルをクリックすることで起動できるはずです。
もし起動できず「ValueError: Timeout value connect was・・・」のようなエラーが発生した場合はurllib3のバージョンが新しすぎる場合があります。
そのような場合は「pip install urllib3==1.26.16」のようにバージョンを下げることで問題なく起動できるようになります。
起動したページの操作
では起動したページを今度は操作していきます。
今回はサイト内にある24時間降水量のcsvファイルをダウンロードするという操作を実施します。
まずサイトへ一度アクセスしてみて、F12を押下して開発者ツールを起動します。
これはサイトがどのようなコードで書かれているかが表示されるものとなっています。
その中の「24時間降水量」は下記の部分に該当しますので、hrefのリンクが貼り付けてある部分を基にコードを書いていきます。

from selenium import webdriver
driver = webdriver.Edge(r"D:\program\python\edgedriver_win64\msedgedriver.exe")
driver.get('https://www.data.jma.go.jp/obd/stats/data/mdrr/pre_rct/alltable/pre24h00_rct.csv')ダウンロード先によっては毎回同じリンクになるとは限りませんが、今回は同様のリンクであった為そのまま記載しています。
毎回リンクが異なるとなるとリンクで指定するよりもidやclassで指定した方がいいと思います。
今回使用した気象庁のホームページにはそういったものがなかったため、とりあえずリンクで指定しています。
これでpythonファイルをクリックすることでダウンロードが開始されます。
以上がスクレイピングを使用したファイルのダウンロードとなります。
最後にスクレイピングを使用する際の注意点として、大量のファイルを一度に同様のサイトからスクレイピングを取得したりすると、相手側のサーバに負荷がかかるのでそこは覚えておいてください。
まとめ
この記事ではpythonを使用したスクレイピングの方法について解説してきました。
- スクレイピングの準備
- edgeを起動してみる
- 起動したページの操作
スクレイピングは一度ツールとして組んでおくことで以降自動化することができる優れものです。
タスクスケジューラやダウンロード後のインストール操作用のバッチファイルなどと組み合わせることでさらなる自動化も実現できます。(私は仕事で実際にそうしていました)
ただ一度に多くのファイルを同様のサイトから取得したりすると相手のサーバに高負荷がかかるため、そこは気を付けて使用してください。
以上でこの記事での解説は終了します。


コメント